2018年考研试题
2017-2018学年北京大学高等代数实验班期末试题2018.1.9
2018.1.9 上午8:30--10:30\\
安金鹏
据悉今年使用的教材是 K. Hoffman, R. Kunze: Linear Algebra
反响好我再发出期中试卷
一、设矩阵$A\in \mathbb{R}^{4\times 4}$的矩阵元均为$1$或$-1$, 求$\det A$的最大值.
二、设$V$是所有从有限域$F_p$到自身的映射构成的$F_p$-线性空间. 定义$T, U\in L(V)$为
$$ T(f)(t)=f(-t), \ \ U(f)(t)=f(t+1)-f(t), \ \ \forall \ f\in V, t\in F_p.$$
求$\det T$和$\det U$.
三、设$V$是有限维$F$-空间, $W$是$V$的子空间, $T\in L(V)$满足$T(W)\subset W$. 定义$T_W\in L(W)$和$T_{V/W}\in L(V/W)$为
$$T_W(\alpha)=T(\alpha), \alpha\in W,$$
$$T_{V/W}(\alpha+W)=T(\alpha)+W, \alpha\in V.$$
证明$\det T=\det T_W \det T_{V/W}$.
四、设$A\in F^{n\times n}$, $V$和$W$是$F^n$的子空间. 证明下述等价:
(a) 对任意的$a\in V-\{0\}$, 存在$\beta\in W$使得$\alpha A\beta^t\neq 0$.
(b) 对任意的$\gamma\in F^n$, 存在$\beta\in W$使得对任意的$\alpha\in V$有$\alpha V\beta^t=\alpha\gamma^t$.
五、设$F$是无限域. 证明对多项式代数$F[x]$的任意有限维子空间$V$, 存在$F[x]$的理想$M$满足
$$V\cap M=\{0\}, \ \ \ V+M=F[x].$$
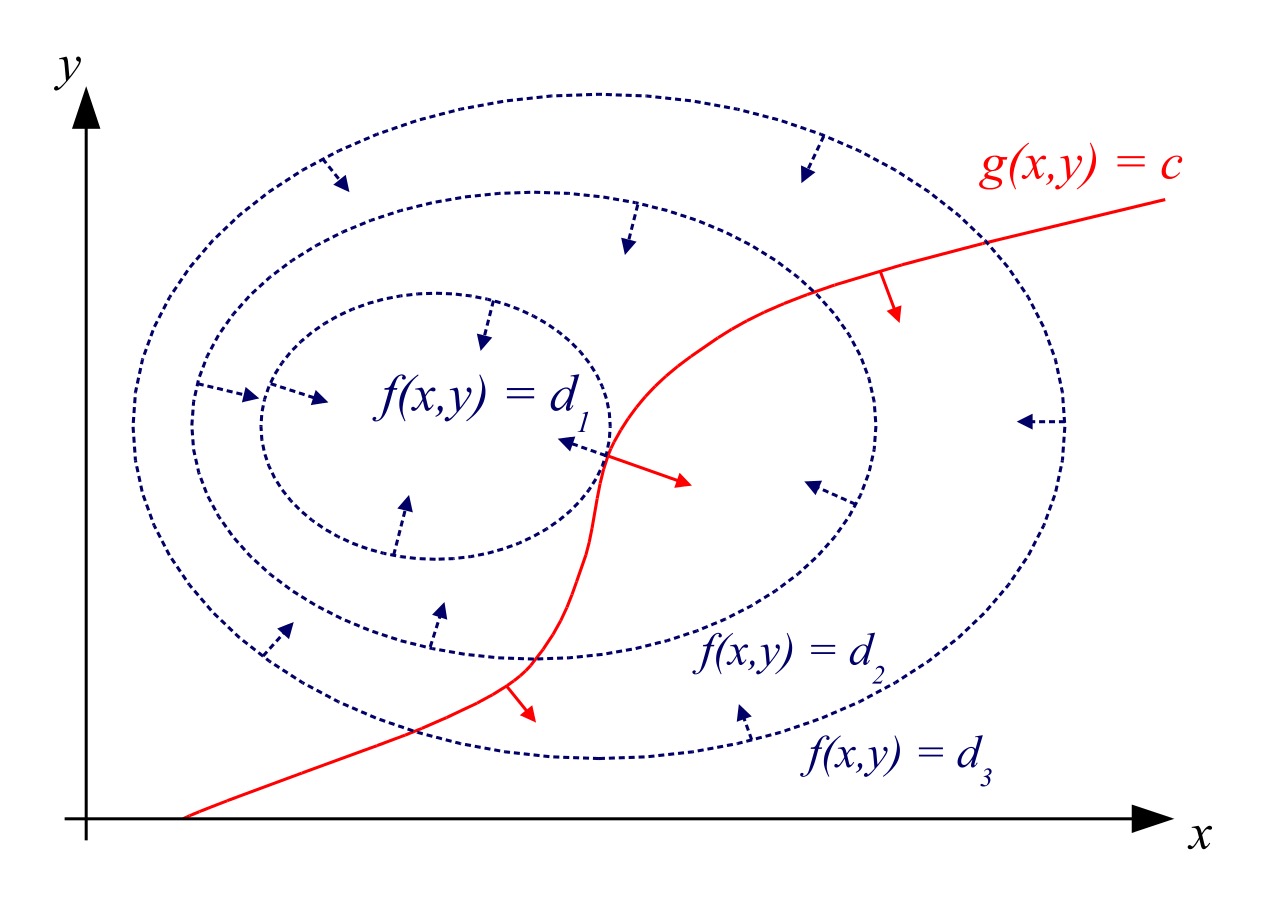
“火腿三明治定理”是什么?
醉鬼能回家,但喝醉的鸟儿可能永远回不了家!
拉格朗日乘数法
相亲问题与倒向归纳法
问题:假设你是一位大龄男士,准备参加 100 场相亲(别介意具体数字)。你打算依次与每个女士 i 约会,然后根据印象给她打一个分数 X_i,X_i 的值介于 [0,1] 之间。如果你对女士 i 很满意,那么就和她结婚,否则就放弃她,参加下一场相亲,当然拒绝了人家可就没有回头的机会了。如果你拒绝了前 99 位女士,那么不论第 100 次相亲结果如何你都只能和最后这位女士结婚。在相亲之前,你对这些女士的情况一无所知,所以姑且假定她们的分数 X_i 都是 [0,1] 上均匀分布的独立的随机变量。问题是:应该采取怎样的相亲策略,才能娶到你最中意的女士?
再费点笔墨解释下。每次相亲结束以后,你可以选择和当前的女士结婚,或者继续见下一位女士,这依赖于你已经相亲的结果:如果你挑挑拣拣到了 90 号女士还拿不定注意,最后发现 “天啊,我快要变剩男了!” 那很可能接下来你就会放低择偶标准,遇到一个还凑合的就结婚了,即使她比你前面拒绝过的很多女士都有不如。当然也不排除你对第一位女士就一见钟情的可能,因此你最终选择的女士的编号 \tau 是一个随机变量,你要做的就是让你的未来太太的期望分数 \mathbb{E}X_\tau 尽可能的高。
那么应该采取怎样的策略为好呢?就像买东西讨价还价时总有一个心理价位一样,应该设定一个心理的期望值,如果遇到的女士的分数大于等于这个值,那就和她结婚;否则就继续下一位女士。这个思路很合理,但是问题是,期望值应该设定为多少呢?
在概率论里面我们学过如下关于顺序统计量的经典结论:设 X_1,\cdots,X_N 是 [0,1] 上独立同分布的均匀随机变量,则 Y=\max\limits_{1\leq i\leq N}X_i 的期望是 \frac{N}{N+1}。在我们的场景中 N=100,所以如果你把 100 次相亲全部进行完,得分最高的女士的期望值理论上应该是 \frac{100}{101},于是你应该把心理门槛设置在 \frac{100}{101},是这样吗?
答案是 NO!首先门槛值应该是一个随着相亲的进行而逐渐降低的数列,这才符合实际的情形:如果前面太挑剔,为了不当剩男你后面的标准就会放低。其次我们会用倒向归纳法计算出最优策略下初始的门槛值并不是最中意的女士的期望值 \frac{100}{101},实际上它更接近于得分第二高的女士的期望值 \frac{99}{101}。这也和现实相符:和你结婚往往不是你最中意的那一个,这就是为什么有那么多婚外情的故事。(The story of the other woman)
倒向归纳法
相亲问题是应用倒向归纳法的一个典型例子。
我们从最后的情形开始分析,假设只剩下一位女士可选,那么你只能去和她结婚,而她的期望值是 1/2,我们记作 a_1=1/2。
假设还剩下两位女士可选呢?这种情况下应该先和其中一个相亲,如果她的分数大于等于 1/2,那就应该和她结婚(后者的期望只有 1/2,很可能不如她),而小于 1/2 的话则去和第二位女士相亲(后者的期望是 1/2,所以我没道理现在娶一个分数小于 1/2 的)。而第一位女士分数大于等于 1/2 的概率是 1/2,在大于等于 1/2 的条件下她的分数服从 [1/2,1] 上的均匀分布,期望值是 3/4。所以你以 1/2 的概率娶到一个期望值为 3/4 的女士,以 1/2 的概率娶到一个期望值为 1/2 的女士。因此有两位女士可选时这个策略的期望分数为
同理,假设还剩下 i 位女士的时候你的心理期望值是 a_i, 我们来导出 a_i 和 a_{i+1} 之间的递推关系:首先和其中一位女士相亲,如果她的分数大于等于 a_i 那么就和她结婚,否则就拒绝她(因为后面 i 个人的心理期望是 a_i,我没道理现在娶一个分数小于 a_i 的)。前一种情形的期望是 \frac{1+a_i}{2} 但是发生的概率是 1-a_i,后一种情形的期望是 a_i 发生的概率也是 a_i,因此
结合初值 a_1=\frac{1}{2} 就可以算出整个序列来,因此我们的相亲策略应该是:
如果当前女士(假设编号为 i)的得分大于等于 a_{101-i},那么就和她结婚;否则就继续去见下一位女士。这里序列 \{a_i\} 由 a_1=1/2,a_{i+1}=\frac{1+a_i^2}{2} 给出。
在这个策略下,你最终娶到的女士得分期望是 a_{100}。
序列 \{a_n\} 的通项公式是求不出来的,只能用计算机来算,这种序列叫做所谓的 Quadratic Map。不过可以估计出 a_{N} 的值小于最优女士的期望值 \frac{N}{N+1} 而且更接近于次优女士的期望值 \frac{N-1}{N+1},这印证了之前说过的:和你结婚的往往不是你最中意的那个。
请注意,虽然我们已经设计出了一个不错的策略,但这个策略到底是不是最优的呢?我们还没有严格证明。而且就算这个策略是最优的,是否只有这一种最优策略呢?没准还有其它最优策略能让你更省时省心地娶到好太太呢!要严格的解释这些,就要用到鞅的理论。
FBI Warning: 接下来的内容要用到概率论中鞅的知识,这通常属于数学专业研究生阶段的内容。
转换为鞅的语言
问题:设 N 是一个给定的正整数,\{\mathcal{F}_n\}_{n=0}^N 是某概率空间上的递增的 \sigma- 域流,\{X_n\}_{n=0}^N 是一列可积的随机变量且 X_k\in\mathcal{F}_k。设 \mathcal{M} 是所有满足 0\leq\tau\leq N 的停时 \tau 组成的集合。我们想求出值函数
V= \sup_{\tau\in\mathcal{M}} \mathbb{E}X_\tau以及使得这个最大值取到的停时 \tau。
定义 \{X_n\} 的 Snell 包络为
这里的 S_n 是从 N 开始倒向递归定义的。注意 S_n 关于 \mathcal{F}_n 可测。
S_n 的直观意义很好理解,就是在时刻 n 对最佳收益的估计:如果过程在当前时刻结束,那么收益就是 X_n;否则继续前进到下一个时刻 n+1,其期望收益是 \mathbb{E}[S_{n+1}|\mathcal{F}_n](注意这里的条件期望不可少,一般来说 \{X_n\} 之间不是独立的,根据前 n 个时刻获得的信息不同,你在 n+1 时刻对最佳收益的估计也可能不同),二者取最大值即为 n 时刻对最佳收益的估计。
设 \tau=\inf\,\{n:\, S_n=X_n\},则 \tau 是停时。注意由于 S_N=X_N,因此 \tau 的定义合理且 0\leq\tau\leq N。\tau 的直观意义就是我们应该采取的最优停止策略:每个时刻,用当前的 X_n 与未来的期望收益 \mathbb{E}[S_{n+1}|\mathcal{F}_n] 比较,见好就收。
定理 1:\{S_n\} 是控制 \{X_n\} 的最小上鞅。
证明:由 S_n 的定义直接可见 S_n\geq X_n 以及 \{S_n\} 是上鞅。设 \{Y_n\} 是另一个上鞅且满足 Y_n\geq X_n,我们要证明必有 Y_n\geq S_n。这只要从最后一项 n=N 开始看即可。由定义 Y_N\geq X_N=S_N,这一项没问题。假设 Y_n\geq S_n,两边对 \mathcal{F}_{n-1} 取条件期望可得
其中第一个不等号是因为 \{Y_n\} 是一个上鞅。再结合 Y_{n-1}\geq X_{n-1} 便有 Y_{n-1}\geq S_{n-1},这样递推下来就有 Y_n\geq S_n 对所有 n=N,N-1,\ldots,0 成立。证毕。
那么怎么证明 \tau 确实是最优的停止策略呢?想法是这样的:设 T 是任意停时,我们要证明 \mathbb{E}X_\tau\geq \mathbb{E}X_T,为此我们利用 \{S_n\} 和 \{X_n\} 的关系,给式子中间塞进去两项,搭一座桥:
注意第一个等号是根据 \tau 的定义,最后一个不等号是根据定理 1。所以我们只要证明中间的不等号 \mathbb{E}S_\tau\geq \mathbb{E}S_T 即可。
我们已经知道 \{S_n\} 是一个上鞅,那么自然不管什么停时 T,统统都有 \mathbb{E}S_T\leq \mathbb{E}S_0。但是关于 \tau 我们可以说的更多:
定理 2:\{S_{n\wedge\tau}\} 是一个鞅。
证明:
对上式右边求条件期望,
这是因为如果 \tau>n 的话那么由 \tau 的定义 S_n=\mathbb{E}[S_{n+1}|\mathcal{F}_n]。
既然如此,那么就有 \mathbb{E}S_\tau=\mathbb{E}S_0,这样就证明了 \tau 的最优性:
定理 3:设 \mathcal{M} 是所有满足 0\leq T\leq N 的停时 T 组成的集合,则 \tau 是其中最优的:
\mathbb{E}S_0=\mathbb{E}X_\tau=\sup_{T\in\mathcal{M}}\mathbb{E}X_T.
至此我们就从数学上严格的论证了为什么前面相亲问题中我们设计的策略是最优的。
如果你回顾一下上面的分析就会发现,我们实际上使用了 \tau 的两个性质:S_\tau=X_\tau和 \{S_{n\wedge\tau}\} 是鞅。这两个性质就保证了 \tau 是最优的停时。那么这是不是说明还有其它最优的策略呢?
定理 4:\nu\in\mathcal{M} 是最优停时的充要条件是: 1. S_\nu=X_\nu。 2. \{S_{n\wedge\nu}\} 是鞅。
定理的必要性告诉我们前面采用的 “见好就收” 策略是所有最优停时中最小的:设 \nu 是任一最优停时,则 \tau\leq\nu(回顾一下 \tau 的定义)。换句话说,我们之前设计的相亲策略是所有最优策略中时间成本最低的!
我们还可以给出最优停止策略中 “最大” 的一个来:
定理 5:设 S_n=M_n+A_n 是 \{S_n\} 的 Doob - Meyer 分解,其中 \{M_n\} 是鞅,A_n 是可料递增过程,定义
\tau_\max = \begin{cases}N & A_N=0,\\ \inf\{n\ |\ A_{n+1}>0\} & A_N>0.\end{cases}则 \tau_\max 是所有最优停时中最大的。
定理 4,5 的证明都不难,这里就省略了。
参考文献
Risk-Neutral Valuation: Pricing and Hedging of Financial Derivatives. By Nicholas H. Bingham, Rüdiger Kiesel.
Hurwitz 平方和定理
连分数理论
1.
向老师的题目
解.先作换元$x\to\tanh x$,可得
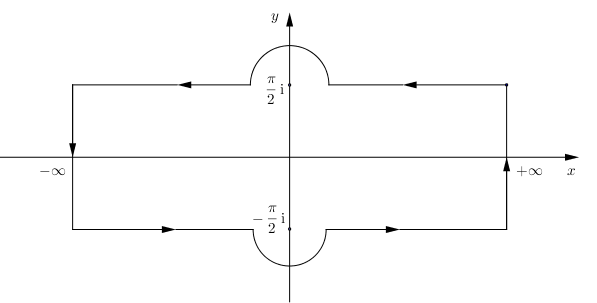

设$\displaystyle{\mathrm{Si}(x)=\int_0^x\frac{\sin t}t\mathrm dt}$表示正弦积分函数,求和
解.[原创]
设$\displaystyle{\mathrm{Si}(x)=\int_0^x\frac{\sin t}t\mathrm dt}$表示正弦积分函数,求和
解.同上,先分部积分得
好吧,算到这里,虽然解决了这三个美国数学月刊征解题,但是干脆再无聊点,下面我们算两个五次方的级数,其实套路都一样,但是计算量增加很多.
从\begin{align*}\text{Si}\left( n\pi \right) &=\int_0^{n\pi}{\frac{\sin t}{t}\text{d}t}=\int_0^{\pi}{\frac{\sin nx}{x}\text{d}x}=\int_0^{\pi}{\sin nx\text{d}\left( \ln x \right)}=-n\int_0^{\pi}{\cos nx\ln x\text{d}x}\\&=-n\int_0^{\pi}{\cos nx\text{d}\left( x\ln x-x \right)}=n\left[ \left( -1 \right) ^{n-1}\left( \pi \ln \pi -\pi \right) -n\int_0^{\pi}{\sin nx\left( x\ln x-x \right) \text{d}x} \right]\end{align*}
最后再算一个级数
解.首先
注:从这里,其实我们发现了对任意整数$k$,$\displaystyle{\sum_{n=1}^{\infty}{\frac{\text{Si}\left( n\pi \right)}{n^{2k-1}}}(k>1),\sum_{n=1}^{\infty}{\left( -1 \right) ^{n-1}\frac{\text{Si}\left( n\pi \right)}{n^{2k-1}}},\sum_{n=1}^{\infty}{\frac{\text{Si}^2\left( n\pi \right)}{n^{2k}}}}$都可以算出来,只是当次数增加时,这个计算量会越来越大,所以再往上算的话估计只有欧拉和拉马努金这种人去了,不知道这个结果是否可以用类似伯努利数的方法给出通项呢?我也解决不了.
如何开启深度学习之旅?这三大类125篇论文为你导航(附资源下载)
选自Github
作者:songrotek
机器之心编译
参与:晏奇、黄小天
如果你现在还是个深度学习的新手,那么你问的第一个问题可能是「我应该从哪篇文章开始读呢?」在 Github 上,songrotek 准备了一套深度学习阅读清单,而且这份清单在随时更新。至于文中提到的 PDF,读者们可点击阅读原文下载机器之心打包的论文,或点开下面的项目地址下载自己喜欢的学习材料。
项目地址:https://github.com/songrotek/Deep-Learning-Papers-Reading-Roadmap
这份清单依照下述 4 条原则建立:
· 从整体轮廓到细节
· 从过去到当代
· 从一般到具体领域
· 聚焦当下最先进技术
你会发现很多非常新但很值得一读的论文。这份清单我会持续更新。
1、深度学习的历史与基础知识
1.0 书籍
[0] Bengio, Yoshua, Ian J. Goodfellow, and Aaron Courville. 深度学习(Deep learning), An MIT Press book. (2015). (这是深度学习领域的圣经,你可以在读此书的同时阅读下面的论文)。
1.1 调查类:
[1] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 深度学习 (Deep learning), Nature 521.7553 (2015): 436-444. (深度学习三位大牛对各种学习模型的评价)
1.2 深度信念网络(DBN)(深度学习前夜的里程碑)
[2] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. 一个关于深度信念网络的快速学习算法(A fast learning algorithm for deep belief nets), (深度学习的前夜)
[3] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. 使用神经网络降低数据的维度(Reducing the dimensionality of data with neural networks), (里程碑式的论文,展示了深度学习的可靠性)
1.3 ImageNet 的演化(深度学习从这里开始)
[4] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 使用深度卷积神经网络进行 ImageNet 分类任务(Imagenet classification with deep convolutional neural networks)(AlexNet, 深度学习的突破)
[5] Simonyan, Karen, and Andrew Zisserman. 针对大尺度图像识别工作的的超深卷积网络(Very deep convolutional networks for large-scale image recognition) (VGGNet, 神经网络开始变得非常深!)
[6] Szegedy, Christian, et al. 更深的卷积(Going deeper with convolutions)(GoogLeNet)
[7] He, Kaiming, et al. 图像识别的深度残差学习(Deep residual learning for image recognition)(ResNet,超级超级深的深度网络!CVPR--IEEE 国际计算机视觉与模式识别会议-- 最佳论文)
1.4 语音识别的演化
[8] Hinton, Geoffrey, et al. 语音识别中深度神经网络的声学建模(Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups)(语音识别中的突破)
[9] Graves, Alex, Abdel-rahman Mohamed, and Geoffrey Hinton. 用深度循环神经网络进行语音识别(Speech recognition with deep recurrent neural networks)(RNN)
[10] Graves, Alex, and Navdeep Jaitly. 面向端到端语音识别的循环神经网络(Towards End-To-End Speech Recognition with Recurrent Neural Networks)
[11] Sak, Haşim, et al. 语音识别中快且精准的循环神经网络声学模型(Fast and accurate recurrent neural network acoustic models for speech recognition)(谷歌语音识别系统)
[12] Amodei, Dario, et al. Deep speech 2:英语和汉语的端到端语音识别(Deep speech 2: End-to-end speech recognition in english and mandarin)(百度语音识别系统)
[13] W. Xiong, J. Droppo, X. Huang, F. Seide, M. Seltzer, A. Stolcke, D. Yu, G. Zweig,在对话语音识别中实现人类平等(Achieving Human Parity in Conversational Speech Recognition) (最先进的语音识别技术,微软)
当你读完了上面给出的论文,你会对深度学习历史有一个基本的了解,深度学习建模的基本架构(包括了 CNN,RNN,LSTM)以及深度学习如何可以被应用于图像和语音识别问题。下面的论文会让你对深度学习方法,不同应用领域中的深度学习技术和其局限有深度认识。我建议你可以基于自己的兴趣和研究方向选择下面这些论文。
2 深度学习方法
2.1 模型
[14] Hinton, Geoffrey E., et al. 通过避免特征检测器的共适应来改善神经网络(Improving neural networks by preventing co-adaptation of feature detectors)(Dropout)
[15] Srivastava, Nitish, et al. Dropout:一种避免神经网络过度拟合的简单方法(Dropout: a simple way to prevent neural networks from overfitting)
[16] Ioffe, Sergey, and Christian Szegedy. Batch normalization:通过减少内部协变量加速深度网络训练(Batch normalization: Accelerating deep network training by reducing internal covariate shift)(2015 年一篇杰出论文)
[17] Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton.层归一化(Layer normalization)(批归一化的升级版)
[18] Courbariaux, Matthieu, et al. 二值神经网络:训练神经网络的权重和激活约束到正 1 或者负 1(Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to+ 1 or−1)(新模型,快)
[19] Jaderberg, Max, et al. 使用合成梯度的解耦神经接口(Decoupled neural interfaces using synthetic gradients)(训练方法的发明,令人惊叹的文章)
[20] Chen, Tianqi, Ian Goodfellow, and Jonathon Shlens. Net2net:通过知识迁移加速学习(Net2net: Accelerating learning via knowledge transfer) (修改之前的训练网络以减少训练)
[21] Wei, Tao, et al. 网络形态(Network Morphism)(修改之前的训练网络以减少训练 epoch)
2.2 优化
[22] Sutskever, Ilya, et al. 有关深度学习中初始化与动量因子的研究(On the importance of initialization and momentum in deep learning) (动量因子优化器)
[23] Kingma, Diederik, and Jimmy Ba. Adam:随机优化的一种方法(Adam: A method for stochastic optimization)(可能是现在用的最多的一种方法)
[24] Andrychowicz, Marcin, et al. 通过梯度下降学习梯度下降(Learning to learn by gradient descent by gradient descent) (神经优化器,令人称奇的工作)
[25] Han, Song, Huizi Mao, and William J. Dally. 深度压缩:通过剪枝、量子化训练和霍夫曼代码压缩深度神经网络(Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding) (ICLR 最佳论文,来自 DeePhi 科技初创公司,加速 NN 运行的新方向)
[26] Iandola, Forrest N., et al. SqueezeNet:带有 50x 更少参数和小于 1MB 模型大小的 AlexNet-层级精确度(SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 1MB model size.) (优化 NN 的另一个新方向,来自 DeePhi 科技初创公司)
2.3 无监督学习/深度生成模型
[27] Le, Quoc V. 通过大规模无监督学习构建高级特征(Building high-level features using large scale unsupervised learning.) (里程碑,吴恩达,谷歌大脑,猫)
[28] Kingma, Diederik P., and Max Welling. 自动编码变异贝叶斯(Auto-encoding variational bayes.) (VAE)
[29] Goodfellow, Ian, et al. 生成对抗网络(Generative adversarial nets.)(GAN, 超酷的想法)
[30] Radford, Alec, Luke Metz, and Soumith Chintala. 带有深度卷曲生成对抗网络的无监督特征学习(Unsupervised representation learning with deep convolutional generative adversarial networks.)(DCGAN)
[31] Gregor, Karol, et al. DRAW:一个用于图像生成的循环神经网络(DRAW: A recurrent neural network for image generation.) (值得注意的 VAE,杰出的工作)
[32] Oord, Aaron van den, Nal Kalchbrenner, and Koray Kavukcuoglu. 像素循环神经网络(Pixel recurrent neural networks.)(像素 RNN)
[33] Oord, Aaron van den, et al. 使用像素 CNN 解码器有条件地生成图像(Conditional image generation with PixelCNN decoders.) (像素 CNN)
2.4 RNN/序列到序列模型
[34] Graves, Alex. 带有循环神经网络的生成序列(Generating sequences with recurrent neural networks.)(LSTM, 非常好的生成结果,展示了 RNN 的力量)
[35] Cho, Kyunghyun, et al. 使用 RNN 编码器-解码器学习词组表征用于统计机器翻译(Learning phrase representations using RNN encoder-decoder for statistical machine translation.) (第一个序列到序列论文)
[36] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. 运用神经网路的序列到序列学习(Sequence to sequence learning with neural networks.」)(杰出的工作)
[37] Bahdanau, Dzmitry, KyungHyun Cho, and Yoshua Bengio. 通过共同学习来匹配和翻译神经机器翻译(Neural Machine Translation by Jointly Learning to Align and Translate.)
[38] Vinyals, Oriol, and Quoc Le. 一个神经对话模型(A neural conversational model.)(聊天机器人上的序列到序列)
2.5 神经图灵机
[39] Graves, Alex, Greg Wayne, and Ivo Danihelka. 神经图灵机器(Neural turing machines.)arXiv preprint arXiv:1410.5401 (2014). (未来计算机的基本原型)
[40] Zaremba, Wojciech, and Ilya Sutskever. 强化学习神经图灵机(Reinforcement learning neural Turing machines.)
[41] Weston, Jason, Sumit Chopra, and Antoine Bordes. 记忆网络(Memory networks.)
[42] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. 端到端记忆网络(End-to-end memory networks.)
[43] Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. 指示器网络(Pointer networks.)
[44] Graves, Alex, et al. 使用带有动力外部内存的神经网络的混合计算(Hybrid computing using a neural network with dynamic external memory.)(里程碑,结合上述论文的思想)
2.6 深度强化学习
[45] Mnih, Volodymyr, et al. 使用深度强化学习玩 atari 游戏(Playing atari with deep reinforcement learning.) (第一篇以深度强化学习命名的论文)
[46] Mnih, Volodymyr, et al. 通过深度强化学习达到人类水准的控制(Human-level control through deep reinforcement learning.) (里程碑)
[47] Wang, Ziyu, Nando de Freitas, and Marc Lanctot. 用于深度强化学习的决斗网络架构(Dueling network architectures for deep reinforcement learning.) (ICLR 最佳论文,伟大的想法 )
[48] Mnih, Volodymyr, et al. 用于深度强化学习的异步方法(Asynchronous methods for deep reinforcement learning.) (当前最先进的方法)
[49] Lillicrap, Timothy P., et al. 运用深度强化学习进行持续控制(Continuous control with deep reinforcement learning.) (DDPG)
[50] Gu, Shixiang, et al. 带有模型加速的持续深层 Q-学习(Continuous Deep Q-Learning with Model-based Acceleration.)
[51] Schulman, John, et al. 信赖域策略优化(Trust region policy optimization.) (TRPO)
[52] Silver, David, et al. 使用深度神经网络和树搜索掌握围棋游戏(Mastering the game of Go with deep neural networks and tree search.) (阿尔法狗)
2.7 深度迁移学习/终身学习/尤其对于 RL
[53] Bengio, Yoshua. 表征无监督和迁移学习的深度学习(Deep Learning of Representations for Unsupervised and Transfer Learning.) (一个教程)
[54] Silver, Daniel L., Qiang Yang, and Lianghao Li. 终身机器学习系统:超越学习算法(Lifelong Machine Learning Systems: Beyond Learning Algorithms.) (一个关于终生学习的简要讨论)
[55] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 提取神经网络中的知识(Distilling the knowledge in a neural network.) (教父的工作)
[56] Rusu, Andrei A., et al. 策略提取(Policy distillation.) (RL 领域)
[57] Parisotto, Emilio, Jimmy Lei Ba, and Ruslan Salakhutdinov. 演员模仿:深度多任务和迁移强化学习(Actor-mimic: Deep multitask and transfer reinforcement learning.) (RL 领域)
[58] Rusu, Andrei A., et al. 渐进神经网络(Progressive neural networks.)(杰出的工作,一项全新的工作)
2.8 一次性深度学习
[59] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. 通过概率程序归纳达到人类水准的概念学习(Human-level concept learning through probabilistic program induction.)(不是深度学习,但是值得阅读)
[60] Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. 用于一次图像识别的孪生神经网络(Siamese Neural Networks for One-shot Image Recognition.)
[61] Santoro, Adam, et al. 用记忆增强神经网络进行一次性学习(One-shot Learning with Memory-Augmented Neural Networks ) (一个一次性学习的基本步骤)
[62] Vinyals, Oriol, et al. 用于一次性学习的匹配网络(Matching Networks for One Shot Learning.)
[63] Hariharan, Bharath, and Ross Girshick. 少量视觉物体识别(Low-shot visual object recognition.)(走向大数据的一步)
3 应用
3.1 NLP(自然语言处理)
[1] Antoine Bordes, et al. 开放文本语义分析的词和意义表征的联合学习(Joint Learning of Words and Meaning Representations for Open-Text Semantic Parsing.)
[2] Mikolov, et al. 词和短语及其组合性的分布式表征(Distributed representations of words and phrases and their compositionality.) (word2vec)
[3] Sutskever, et al. 运用神经网络的序列到序列学习(Sequence to sequence learning with neural networks.)
[4] Ankit Kumar, et al. 问我一切:动态记忆网络用于自然语言处理(Ask Me Anything: Dynamic Memory Networks for Natural Language Processing.)
[5] Yoon Kim, et al. 角色意识的神经语言模型(Character-Aware Neural Language Models.)
[6] Jason Weston, et al. 走向人工智能-完成问题回答:一组前提玩具任务(Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks.) (bAbI 任务)
[7] Karl Moritz Hermann, et al. 教机器阅读和理解(Teaching Machines to Read and Comprehend.)(CNN/每日邮件完形风格问题)
[8] Alexis Conneau, et al. 非常深度卷曲网络用于自然语言处理(Very Deep Convolutional Networks for Natural Language Processing.) (在文本分类中当前最好的)
[9] Armand Joulin, et al. 诡计包用于有效文本分类(Bag of Tricks for Efficient Text Classification.)(比最好的差一点,但快很多)
3.2 目标检测
[1] Szegedy, Christian, Alexander Toshev, and Dumitru Erhan. 深度神经网路用于目标检测(Deep neural networks for object detection.)
[2] Girshick, Ross, et al. 富特征层级用于精确目标检测和语义分割(Rich feature hierarchies for accurate object detection and semantic segmentation.)(RCNN)
[3] He, Kaiming, et al. 深度卷曲网络的空间金字塔池用于视觉识别(Spatial pyramid pooling in deep convolutional networks for visual recognition.) (SPPNet)
[4] Girshick, Ross. 快速的循环卷曲神经网络(Fast r-cnn.)
[5] Ren, Shaoqing, et al. 更快的循环卷曲神经网络:通过区域建议网络趋向实时目标检测(Faster R-CNN: Towards real-time object detection with region proposal networks.)
[6] Redmon, Joseph, et al. 你只看到一次:统一实时的目标检测(You only look once: Unified, real-time object detection.) (YOLO, 杰出的工作,真的很实用)
[7] Liu, Wei, et al. SSD:一次性多盒探测器(SSD: Single Shot MultiBox Detector.)
3.3 视觉跟踪
[1] Wang, Naiyan, and Dit-Yan Yeung. 学习视觉跟踪用的一种深度压缩图象表示(Learning a deep compact image representation for visual tracking.) (第一篇使用深度学习进行视觉跟踪的论文,DLT 跟踪器)
[2] Wang, Naiyan, et al. 为稳定的视觉跟踪传输丰富特征层次(Transferring rich feature hierarchies for robust visual tracking.)(SO-DLT)
[3] Wang, Lijun, et al. 用全卷积网络进行视觉跟踪(Visual tracking with fully convolutional networks.) (FCNT)
[4] Held, David, Sebastian Thrun, and Silvio Savarese. 用深度回归网络以 100FPS 速度跟踪(Learning to Track at 100 FPS with Deep Regression Networks.) (GOTURN, 作为一个深度神经网络,其速度非常快,但是相较于非深度学习方法还是慢了很多)
[5] Bertinetto, Luca, et al. 对象跟踪的全卷积 Siamese 网络(Fully-Convolutional Siamese Networks for Object Tracking.) (SiameseFC, 实时对象追踪的最先进技术)
[6] Martin Danelljan, Andreas Robinson, Fahad Khan, Michael Felsberg. 超越相关滤波器:学习连续卷积算子的视觉追踪(Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking.)(C-COT)
[7] Nam, Hyeonseob, Mooyeol Baek, and Bohyung Han. 在视觉跟踪的树结构中传递卷积神经网络与建模(Modeling and Propagating CNNs in a Tree Structure for Visual Tracking.)(VOT2016 Winner,TCNN)
3.4 图像说明
[1] Farhadi,Ali,etal. 每幅图都讲述了一个故事:从图像中生成句子(Every picture tells a story: Generating sentences from images.)
[2] Kulkarni, Girish, et al. 儿语:理解并生成图像的描述(talk: Understanding and generating image deions.)
[3] Vinyals, Oriol, et al. 展示与表达:一个神经图像字幕生成器(Show and tell: A neural image caption generator)
[4] Donahue, Jeff, et al. 视觉认知和描述的长期递归卷积网络(Long-term recurrent convolutional networks for visual recognition and deion)
[5] Karpathy, Andrej, and Li Fei-Fei. 产生图像描述的深层视觉语义对齐(Deep visual-semantic alignments for generating image deions)
[6] Karpathy, Andrej, Armand Joulin, and Fei Fei F. Li. 双向图像句映射的深片段嵌入(Deep fragment embeddings for bidirectional image sentence mapping)
[7] Fang, Hao, et al. 从字幕到视觉概念,从视觉概念到字幕(From captions to visual concepts and back)
[8] Chen, Xinlei, and C. Lawrence Zitnick. 图像字幕生成的递归视觉表征学习「Learning a recurrent visual representation for image caption generation
[9] Mao, Junhua, et al. 使用多模型递归神经网络(m-rnn)的深度字幕生成(Deep captioning with multimodal recurrent neural networks (m-rnn).)
[10] Xu, Kelvin, et al. 展示、参与与表达:视觉注意的神经图像字幕生成(Show, attend and tell: Neural image caption generation with visual attention.)
3.5 机器翻译
一些里程碑式的论文在 RNN 序列到序列的主题分类下被列举。
[1] Luong, Minh-Thang, et al. 神经机器翻译中生僻词问题的处理(Addressing the rare word problem in neural machine translation.)
[2] Sennrich, et al. 带有子词单元的生僻字神经机器翻译(Neural Machine Translation of Rare Words with Subword Units)
[3] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. 基于注意力的神经机器翻译的有效途径(Effective approaches to attention-based neural machine translation.)
[4] Chung, et al. 一个机器翻译无显式分割的字符级解码器(A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation)
[5] Lee, et al. 无显式分割的全字符级神经机器翻译(Fully Character-Level Neural Machine Translation without Explicit Segmentation)
[6] Wu, Schuster, Chen, Le, et al. 谷歌的神经机器翻译系统:弥合人与机器翻译的鸿沟(Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation)
3.6 机器人
[1] Koutník, Jan, et al. 发展用于视觉强化学习的大规模神经网络(Evolving large-scale neural networks for vision-based reinforcement learning.)
[2] Levine, Sergey, et al. 深度视觉眼肌运动策略的端到端训练(End-to-end training of deep visuomotor policies.)
[3] Pinto, Lerrel, and Abhinav Gupta. 超大尺度自我监督:从 5 万次尝试和 700 机器人小时中学习抓取(Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours.)
[4] Levine, Sergey, et al. 学习手眼协作用于机器人掌握深度学习和大数据搜集(Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection.)
[5] Zhu, Yuke, et al. 使用深度强化学习视觉导航目标驱动的室内场景(Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning.)
[6] Yahya, Ali, et al. 使用分布式异步引导策略搜索进行集体机器人增强学习(Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search.)
[7] Gu, Shixiang, et al. 深度强化学习用于机器操控(Deep Reinforcement Learning for Robotic Manipulation.)
[8] A Rusu, M Vecerik, Thomas Rothörl, N Heess, R Pascanu, R Hadsell. 模拟实机机器人使用过程网从像素中学习(Sim-to-Real Robot Learning from Pixels with Progressive Nets.)
[9] Mirowski, Piotr, et al. 学习在复杂环境中导航(Learning to navigate in complex environments.)
3.7 艺术
[1] Mordvintsev, Alexander; Olah, Christopher; Tyka, Mike (2015). 初始主义:神经网络的更深层(Inceptionism: Going Deeper into Neural Networks)(谷歌 Deep Dream)
[2] Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. 一个艺术风格的神经算法(A neural algorithm of artistic style.) (杰出的工作,目前最成功的算法)
[3] Zhu, Jun-Yan, et al. 自然图像流形上的生成视觉操纵(Generative Visual Manipulation on the Natural Image Manifold.)
[4] Champandard, Alex J. Semantic Style Transfer and Turning Two-Bit Doodles into Fine Artworks. (神经涂鸦)
[5] Zhang, Richard, Phillip Isola, and Alexei A. Efros. 多彩的图像彩色化(Colorful Image Colorization.)
[6] Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. 实时风格迁移和超分辨率的感知损失(Perceptual losses for real-time style transfer and super-resolution.)
[7] Vincent Dumoulin, Jonathon Shlens and Manjunath Kudlur. 一个艺术风格的学习表征(A learned representation for artistic style.)
[8] Gatys, Leon and Ecker, et al. 神经风格迁移中的控制感知因子(Controlling Perceptual Factors in Neural Style Transfer.) (控制空间定位、色彩信息和全空间尺度方面的风格迁移)
[9] Ulyanov, Dmitry and Lebedev, Vadim, et al. 纹理网络:纹理和风格化图像的前馈合成(Texture Networks: Feed-forward Synthesis of Textures and Stylized Images.) (纹理生成和风格迁移)
3.8 对象分割
[1] J. Long, E. Shelhamer, and T. Darrell, 用于语义分割的全卷积网络(Fully convolutional networks for semantic segmentation)
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. 具有深度卷积网络和全连接的条件随机场的语义图像分割(Semantic image segmentation with deep convolutional nets and fully connected crfs)
[3] Pinheiro, P.O., Collobert, R., Dollar, P. 学习如何分割候选对象(Learning to segment object candidates)
[4] Dai, J., He, K., Sun, J. 基于多任务网络级联的实例感知语义分割(Instance-aware semantic segmentation via multi-task network cascades)
[5] Dai, J., He, K., Sun, J. 实例敏感的全卷积网络(Instance-sensitive Fully Convolutional Networks)
十个利用矩阵解决的经典题目
来源:http://blog.csdn.net/fun_zero/article/details/48685661
经典题目1 给定n个点,m个操作,构造O(m+n)的算法输出m个操作后各点的位置。操作有平移、缩放、翻转和旋转
这里的操作是对所有点同时进行的。其中翻转是以坐标轴为对称轴进行翻转(两种情况),旋转则以原点为中心。如果对每个点分别进行模拟,那么m个操作总共耗时O(mn)。利用矩阵乘法可以在O(m)的时间里把所有操作合并为一个矩阵,然后每个点与该矩阵相乘即可直接得出最终该点的位置,总共耗时O(m+n)。假设初始时某个点的坐标为x和y,下面5个矩阵可以分别对其进行平移、旋转、翻转和旋转操作。预先把所有m个操作所对应的矩阵全部乘起来,再乘以(x,y,1),即可一步得出最终点的位置。

经典题目2 给定矩阵A,请快速计算出A^n(n个A相乘)的结果,输出的每个数都mod p。
由于矩阵乘法具有结合律,因此A^4 = A * A * A * A = (A*A) * (A*A) = A^2 * A^2。我们可以得到这样的结论:当n为偶数时,A^n = A^(n/2) * A^(n/2);当n为奇数时,A^n = A^(n/2) * A^(n/2) * A (其中n/2取整)。这就告诉我们,计算A^n也可以使用二分快速求幂的方法。例如,为了算出A^25的值,我们只需要递归地计算出A^12、A^6、A^3的值即可。根据这里的一些结果,我们可以在计算过程中不断取模,避免高精度运算。
经典题目3 POJ3233 (感谢rmq)
题目大意:给定矩阵A,求A + A^2 + A^3 + ... + A^k的结果(两个矩阵相加就是对应位置分别相加)。输出的数据mod m。k<=10^9。
这道题两次二分,相当经典。首先我们知道,A^i可以二分求出。然后我们需要对整个题目的数据规模k进行二分。比如,当k=6时,有:
A + A^2 + A^3 + A^4 + A^5 + A^6 =(A + A^2 + A^3) + A^3*(A + A^2 + A^3)
应用这个式子后,规模k减小了一半。我们二分求出A^3后再递归地计算A + A^2 + A^3,即可得到原问题的答案。
POJ3233题解: Matrix Power Series
经典题目4 VOJ1049
题目大意:顺次给出m个置换,反复使用这m个置换对初始序列进行操作,问k次置换后的序列。m<=10, k<2^31。
首先将这m个置换“合并”起来(算出这m个置换的乘积),然后接下来我们需要执行这个置换k/m次(取整,若有余数则剩下几步模拟即可)。注意任意一个置换都可以表示成矩阵的形式。例如,将1 2 3 4置换为3 1 2 4,相当于下面的矩阵乘法:
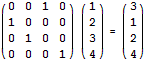
置换k/m次就相当于在前面乘以k/m个这样的矩阵。我们可以二分计算出该矩阵的k/m次方,再乘以初始序列即可。做出来了别忙着高兴,得意之时就是你灭亡之日,别忘了最后可能还有几个置换需要模拟。
经典题目5 《算法艺术与信息学竞赛》207页(2.1代数方法和模型,[例题5]细菌,版次不同可能页码有偏差)
大家自己去看看吧,书上讲得很详细。解题方法和上一题类似,都是用矩阵来表示操作,然后二分求最终状态。
经典题目6 给定n和p,求第n个Fibonacci数mod p的值,n不超过2^31
根据前面的一些思路,现在我们需要构造一个2 x 2的矩阵,使得它乘以(a,b)得到的结果是(b,a+b)。每多乘一次这个矩阵,这两个数就会多迭代一次。那么,我们把这个2 x 2的矩阵自乘n次,再乘以(0,1)就可以得到第n个Fibonacci数了。不用多想,这个2 x 2的矩阵很容易构造出来:
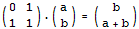
经典题目7 VOJ1067
我们可以用上面的方法二分求出任何一个线性递推式的第n项,其对应矩阵的构造方法为:在右上角的(n-1)*(n-1)的小矩阵中的主对角线上填1,矩阵第n行填对应的系数,其它地方都填0。例如,我们可以用下面的矩阵乘法来二分计算f(n) = 4f(n-1) - 3f(n-2) + 2f(n-4)的第k项:
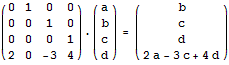
利用矩阵乘法求解线性递推关系的题目我能编出一卡车来。这里给出的例题是系数全为1的情况。
经典题目8 给定一个有向图,问从A点恰好走k步(允许重复经过边)到达B点的方案数mod p的值
把给定的图转为邻接矩阵,即A(i,j)=1当且仅当存在一条边i->j。令C=A*A,那么C(i,j)=ΣA(i,k)*A(k,j),实际上就等于从点i到点j恰好经过2条边的路径数(枚举k为中转点)。类似地,C*A的第i行第j列就表示从i到j经过3条边的路径数。同理,如果要求经过k步的路径数,我们只需要二分求出A^k即可。
经典题目9 用1 x 2的多米诺骨牌填满M x N的矩形有多少种方案,M<=5,N<2^31,输出答案mod p的结果
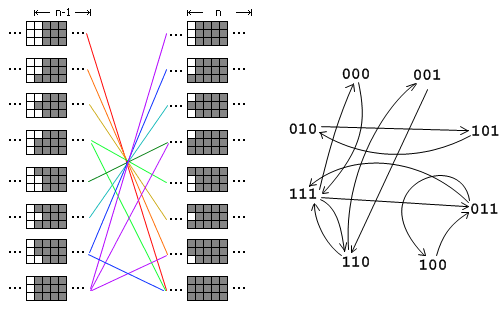
我们以M=3为例进行讲解。假设我们把这个矩形横着放在电脑屏幕上,从右往左一列一列地进行填充。其中前n-2列已经填满了,第n-1列参差不齐。现在我们要做的事情是把第n-1列也填满,将状态转移到第n列上去。由于第n-1列的状态不一样(有8种不同的状态),因此我们需要分情况进行讨论。在图中,我把转移前8种不同的状态放在左边,转移后8种不同的状态放在右边,左边的某种状态可以转移到右边的某种状态就在它们之间连一根线。注意为了保证方案不重复,状态转移时我们不允许在第n-1列竖着放一个多米诺骨牌(例如左边第2种状态不能转移到右边第4种状态),否则这将与另一种转移前的状态重复。把这8种状态的转移关系画成一个有向图,那么问题就变成了这样:从状态111出发,恰好经过n步回到这个状态有多少种方案。比如,n=2时有3种方案,111->011->111、111->110->111和111->000->111,这与用多米诺骨牌覆盖3x2矩形的方案一一对应。这样这个题目就转化为了我们前面的例题8。
后面我写了一份此题的源代码。你可以再次看到位运算的相关应用。
经典题目10 POJ2778
题目大意是,检测所有可能的n位DNA串有多少个DNA串中不含有指定的病毒片段。合法的DNA只能由ACTG四个字符构成。题目将给出10个以内的病毒片段,每个片段长度不超过10。数据规模n<=2 000 000 000。
下面的讲解中我们以ATC,AAA,GGC,CT这四个病毒片段为例,说明怎样像上面的题一样通过构图将问题转化为例题8。我们找出所有病毒片段的前缀,把n位DNA分为以下7类:以AT结尾、以AA结尾、以GG结尾、以?A结尾、以?G结尾、以?C结尾和以??结尾。其中问号表示“其它情况”,它可以是任一字母,只要这个字母不会让它所在的串成为某个病毒的前缀。显然,这些分类是全集的一个划分(交集为空,并集为全集)。现在,假如我们已经知道了长度为n-1的各类DNA中符合要求的DNA个数,我们需要求出长度为n时各类DNA的个数。我们可以根据各类型间的转移构造一个边上带权的有向图。例如,从AT不能转移到AA,从AT转移到??有4种方法(后面加任一字母),从?A转移到AA有1种方案(后面加个A),从?A转移到??有2种方案(后面加G或C),从GG到??有2种方案(后面加C将构成病毒片段,不合法,只能加A和T)等等。这个图的构造过程类似于用有限状态自动机做串匹配。然后,我们就把这个图转化成矩阵,让这个矩阵自乘n次即可。最后输出的是从??状态到所有其它状态的路径数总和。
题目中的数据规模保证前缀数不超过100,一次矩阵乘法是三方的,一共要乘log(n)次。因此这题总的复杂度是100^3 * log(n),AC了。